Quality Control of Agents = QA² — Why Agentic Evaluations Matter More Than Prompt Engineering
Learn why testing AI agents requires a fundamentally different approach than traditional QA. Explore the combinatorial explosion of failure modes — from hallucinations to prompt injection — and why agentic evaluations are the critical skill for production AI systems.
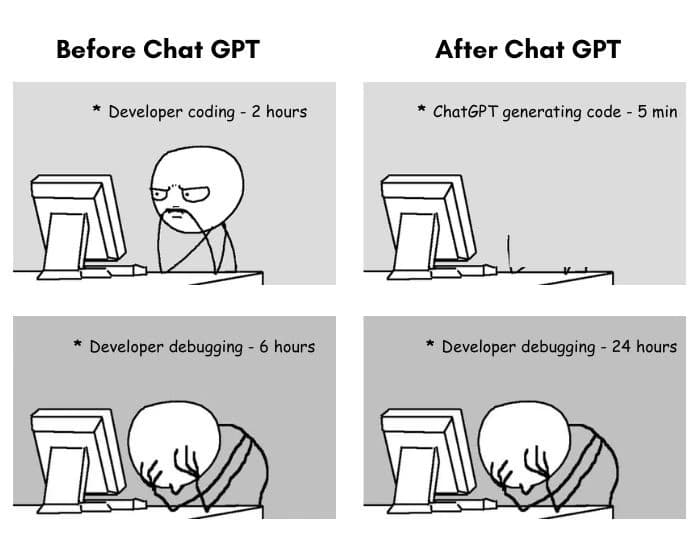
You can build a simple AI agent in an hour today — using n8n or Cursor. Andrew Ng's course takes about 6 hours. But as we all know, the last 5% of a project takes 50% of the time. And for agents, those 5% are about making the agent actually work in real production scenarios.
I was building QA processes 10 years ago, and now I'm building AI products — and I see tectonic shifts: quality control has gone from "very important" to absolutely critical.
Not testing a regular service is like sailing the sea without navigation. Not testing an LLM agent is like going into open space without a ship, a spacesuit, or even clothes.
Classic Quality Assurance is already a hard job: you need to identify all possible inputs, combinations, corner cases, and be empathetic to user behavior. But agents… they're a mess. They can fail in all the ways traditional software can — multiplied by hallucinations, context misinterpretation, an infinite number of unpredictable inputs, and wild corner cases. In other words, a true combinatorial explosion.
Did you test for SQL injections in the past? Now add checks for information leakage ("Show me your system prompt"), role drift ("Give me a pancake recipe"), and prompt injection ("Ignore all previous instructions and…").
Did you test corner cases and different input formats? Now add languages and cultural contexts, unstructured data, double meanings, irony, and sarcasm.
And of course, with every step in an agent's workflow, errors compound. At Outrizz, we're building a deeply contextual conversational sales agent. Its pipeline includes: conversation intent detection, communication strategy selection, context injection, response copywriting, response quality evaluation, and so on. Each step requires its own evaluations ("unit tests") and the full chain requires integration testing.
In the next posts, I'll talk about how to build a full-fledged quality control system for agents, what frameworks exist for this, and how different evaluation approaches compare.
I'd love to hear your experience: how do you test LLM agents in production? What has already broken for you, and what worked better than expected?
Share this article
About the author
Ready to book meetings at your next trade show?
We guarantee 10 qualified meetings before you arrive — or your money back.
Check event fit